
LiLa: Linking Latin
Building a Knowledge Base of Linguistic Resources for Latin
LiLa: Linking Latin is an ERC-Consolidator Grant project (2018-2023) hosted at the CIRCSE research centre of the Università Cattolica del Sacro Cuore, Milan, Italy.
The objective of LiLa is to connect and, ultimately, exploit the wealth of linguistic resources and NLP tools for Latin developed thus far, in order to bridge the gap between raw language data, NLP and knowledge description.
To this aim, the project is building a Linked Data Knowledge Base of linguistic resources and NLP tools for Latin (called LiLa). The Knowledge Base consists of different kinds of objects connected through edges labelled with a restricted set of values taken from a vocabulary of knowledge description.
LiLa collects and connects both existing and newly-generated (meta)data. The former are mostly linguistic resources (corpora, lexica, ontologies, dictionaries, thesauri) and NLP tools (tokenisers, lemmatisers, PoS-taggers, morphological analysers and dependency parsers) for Latin. These are currently available from different providers under different licences. As for the latter, LiLa assesses a set of selected linguistic resources by expanding their lexical and/or textual coverage. In particular, it
a) enhances the Latin texts made available by existing digital libraries and resources with PoS-tagging and lemmatisation, by building a set of newly-trained models for PoS-tagging and lemmatisation, and working on developing/testing the best performing NLP pipeline for such a task;
b) improves the lexical coverage of the Latin WordNet and the valency lexicon Latin-Vallex;
c) expands the textual coverage of the Index Thomisticus Treebank.
In order to achieve interoperability between resources (and tools), LiLa makes use of a set of Semantic Web and Linguistic Linked Open Data standards. The latter include ontologies to describe linguistic annotations (OLiA ), corpus annotation (NIF, CoNLL2RDF) and lexical resources (Lemon). The backbone of LiLa, the collection of Latin lemmas, lexical bases and morphemes, is built from the lists compiled for the LEMLAT morphological analyser and the WFL word formation lexicon of Latin. Their connections, properties and relations are modelled using the OWL language for ontologies.
As can be observed from the simplified conceptual model illustrated in the Figure, the LiLa Knowledge Base is highly lexically-based.
Lemmas are the key node type in the Knowledge Base. Lemmas occur in Lexical Resources (as lexical entries) and have one or more (inflected) Forms. For instance, the lemma puella, ‘girl’ has forms like puellam, puellis and puellas.
Forms, too, can occur in lexical resources; for instance, in a lexicon containing all the word forms of a language. Both Lemmas and Forms can have one or more graphical variants (condicio vs. conditio).
The occurrences of Forms in real texts are Tokens, which are provided by Textual Resources. Texts in Textual Resources can be different editions/versions of the same Work (e.g., the various editions of the Orator by Cicero, possibly provided by different Textual Resources).
Finally,
NLP tools process either Forms
(e.g., a morphological analyser) or Tokens (e.g., a PoS-tagger).
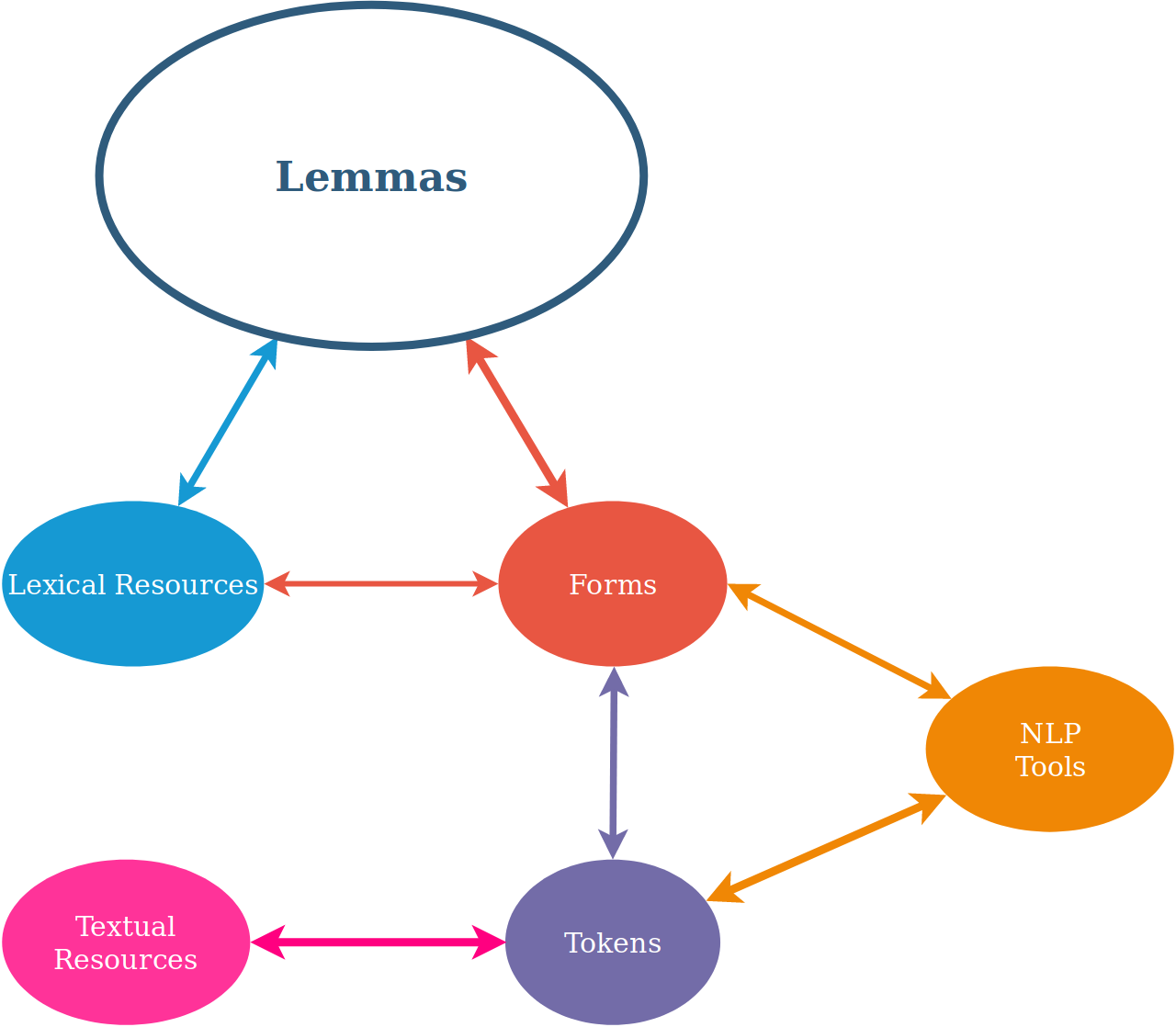
The Conceptual model of LiLa.
Once LiLa will be available, it will be possible, for example, to find all tokens that combine the following requirements:
a) are connected to a lemma with Part-of-Speech Verb of the 1st conjugation (LEMLAT);
b) are connected to a lemma that have prefix de- (WFL);
c) are connected to a lemma that have a valency frame that has at least 3 arguments, of which one has semantic role ORIGIN (Latin Vallex);
d) (d.1) occur in texts by one or multiple authors or (d.2) in a text available in a Universal Dependencies treebank where the token is conjugated in the infinitive and governs directly another noun token in the accusative with dependency relation nsubj (nominal subject).
TEAM
- Marco Passarotti – Principal Investigator
- Eleonora Litta – Researcher
- Francesco Mambrini – Researcher
- Flavio M. Cecchini – Postdoctoral Researcher
- Greta Franzini – Postdoctoral Researcher
- Rachele Sprugnoli – Postdoctoral Researcher
- Paolo Ruffolo – Computer Engineer
- Marinella Testori – Collaborator
- Savina Raynaud – Professor, Collaborator
- Aldo Frigerio – Professor, Collaborator
- Marco Pappalepore – Software Engineer, Collaborator
- Andrea Peverelli – Collaborator, Intern
CONTACTS
Università Cattolica del Sacro Cuore
CIRCSE Research Centre
Largo Gemelli 1, 20123 Milan, Italy
homepage: https://lila-erc.eu/
e-mail: info@lila-erc.eu
phone: +39 02 72342380
